

Introduction
Imagine sitting on a treasure trove of knowledge — but it’s locked away inside millions of PDFs. Engineering drawings, legal contracts, procurement records, and scanned compliance forms often contain valuable information, yet they’re hard to find with regular search tools. Many organizations struggle with this issue — they have piles of content-rich PDFs stored away in file shares and SharePoint sites, but accessing the insights within can be a real challenge. Traditional keyword searches just don’t work well for scanned pages or detailed diagrams.
That’s where our AI-powered PDF intelligence solution comes in. By utilizing tools like FastAPI, Azure AI, and Elasticsearch, we can turn those static files into searchable, dynamic resources that bring important information to light.
The Problem: Information Hidden in Plain Sight
Whether you’re in manufacturing, energy, or the public sector, your teams probably store:
- Technical manuals and engineering drawings
- Supplier RFQs and procurement documents
- Contracts, policy binders, and HR files
- Scanned regulatory forms, inspection checklists
But these are often:
- Scanned images with no machine-readable text
- Inconsistent metadata (missing part numbers, supplier IDs)
- Buried in folder hierarchies no one wants to dig through
The result? Compliance teams spend hours on audits. Engineers reinvent the wheel instead of reusing proven designs. Procurement misses opportunities buried in old RFQs.
Our Solution: An AI-Powered Extraction and Search Workflow
Our pipeline unlocks these static files and injects them into your operations as live, searchable knowledge.
Here’s how it works:
1. Secure Upload & Storage
Users — or automated processes — drop PDFs into a secure Azure File Share. This staging layer feeds the entire pipeline.
2. Chunking for Speed
Large PDFs are split into 10-page chunks using a custom FastAPI microservice. Why? Parallel processing. Instead of waiting for a 500-page contract to finish, chunks are handled simultaneously for maximum throughput.
3. Smart Text Extraction
Azure AI Document Intelligence does the heavy lifting here — OCR unlocks text from scanned pages. Tables and forms? Parsed into structured data automatically.
4. Vision Intelligence for Images
Technical PDFs often include embedded diagrams, schematics, or signatures. Using PyMuPDF, we extract all images and send them to LLaMA-3.2-11B-Vision-Instruct, a cutting-edge Vision Language Model that generates dense, descriptive captions.
This means:
- Drawings are described in text
- Diagrams get context
- Visual content is no longer invisible to search
5. LLM-Powered Synthesis
Next, Meta-LLaMA-3.1-405B-Instruct fuses extracted text and visual captions into one unified, structured JSON. Now, your PDF is more than pages — it’s context-rich, machine-readable data.
6. Aggregate & Optimize
Chunks are stitched back together, temporary files wiped, and the final structured extract is ready for indexing.
7. Lightning-Fast Search in Elasticsearch
Finally, the pipeline pushes the structured output into Elasticsearch. Instantly:
– Search by keyword, part number, revision
– Run semantic queries (e.g., “Find all RFQs mentioning supplier X and product Y”)
– Filter by date, owner, or custom metadata
Explore our AppSource Marketplace offer on a AI Strategy Briefing for extending Copilot for Microsoft 365 and building Custom Copilots
Our Solution: Architecture Overview
To better illustrate how this AI-powered document processing pipeline works end-to-end, the following architecture diagram breaks down the key components and flow:
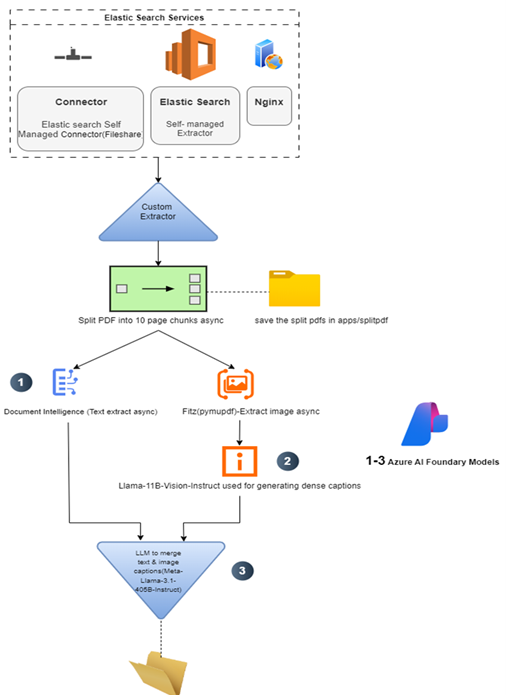
Connector and Elasticsearch Layer:
At the top, our self-managed Elasticsearch services (with NGINX and custom connectors) securely manage storage, indexing, and querying. This foundation ensures your processed document data is always searchable and optimized for performance.
Custom Extractor Service:
Uploaded PDFs enter the Custom Extractor, where they are automatically split into manageable 10-page chunks. These chunks are temporarily saved and processed asynchronously, ensuring fast handling of large files.
Parallel AI Processing:
Each chunk goes through two parallel AI tasks:
- Document Intelligence extracts text and form data.
- Fitz (PyMuPDF) isolates images, and Llama-11B-Vision-Instruct generates rich captions for them.
LLM Synthesis & Cleanup:
A Meta-Llama-3.1-405B-Instruct model merges extracted text and image insights into a single structured format. Once complete, all intermediate split files are cleaned up, leaving only the final enriched extract ready for Elasticsearch indexing.
What This Means for You
✅ Zero guesswork — Find the exact page with the spec you need.
✅ Compliance, turbocharged — Prove what was done, when, and by whom — instantly.
✅ Engineering and procurement re-use — Build on what you have instead of starting over.
Why It Works
- FastAPI Orchestration: Handles concurrency, chunking, and clean-up at scale.
- Azure Document Intelligence: Extracts clean, structured text and tables, even from scans.
- LLaMA & Meta-LLaMA: Add human-like context and understanding to both text and images.
- Elasticsearch: The gold standard for blazing-fast, full-text and semantic search.

Ebook: A Guide to Unlocking Productivity with Generative AI in the Workplace
This eBook, brought to you by Netwoven, a global leader in Microsoft consulting services, explores into the exciting potential of AI at your workplace within the familiar Microsoft 365 suite.
Get the eBookTransform Passive PDFs Into a Living Knowledge Platform
Your document repository doesn’t have to be a liability buried on a server. With this pipeline, it becomes a strategic asset — accessible, actionable, and infused with AI understanding.
Ready to see it in action?
Let’s unlock the full value of your PDFs. Contact our team to learn how we can customize this workflow for your compliance, engineering, or procurement needs.


















