Introduction
Microsoft Fabric Data Warehouse is a cloud-native data warehousing solution that leverages the Polaris distributed SQL query engine.
Polaris is a stateless, interactive relational query engine that powers the Fabric Data Warehouse.
- It is designed to unify data warehousing and big data workloads while segregating compute and state for seamless cloud-native operations Polaris is a distributed analytics system that is optimized for analytical workloads
- It is built from the ground up to serve the needs of today’s data platforms
- It is a columnar, in-memory engine that is highly efficient and handles concurrency well. I hope this helps you understand the inner workings of Microsoft Fabric Data Warehouse and Polaris Engine.
I hope this helps you understand the inner workings of Microsoft Fabric Data Warehouse and Polaris Engine.

Fabric Warehouse – Polaris Analytics Engine
The decoupling of compute and storage in Synapse Dedicated SQL Pool is a significant advantage over Microsoft Fabric Data Warehouse, as it allows for enhanced resource scalability and flexible resource scaling.
In stateful architectures, the state for inflight transactions remains stored in the compute node until the transaction commits, rather than being immediately hardened into persistent storage. As a consequence, in the event of a compute node failure, the state of non-committed transactions becomes lost, leaving no recourse but to terminate in-flight transactions. In summary, stateful architectures inherently lack the capability for resilience to compute node failure and elastic assignment of data to compute resources.
However, decoupling of compute and storage is not the same as decoupling compute and state. In stateless compute architectures, compute nodes are designed to be devoid of any state information, meaning all data, transactional logs, and metadata must reside externally. This approach enables the application to partially restart query execution in case of compute node failures and smoothly adapt to real-time changes in cluster topology without disrupting in-flight transactions.
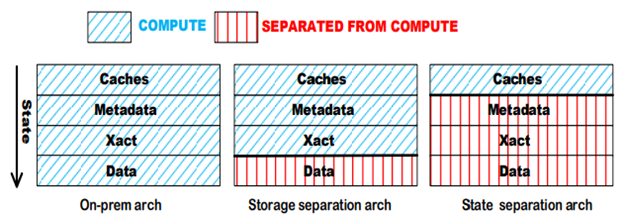
The evolution of data warehouse architectures over the years.
Data abstraction
Polaris represents data using a “cell” abstraction with two dimensions:
- Distributions (data alignment)
- Partitions (data prunining)
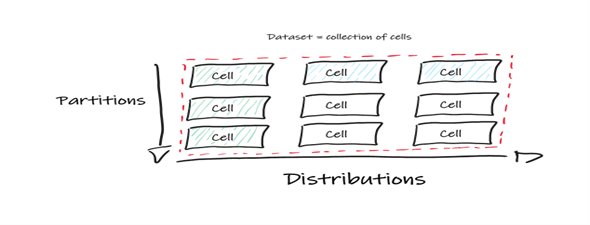
Polaris significantly elevates the optimizer framework in SQL Server by introducing cell awareness, where each cell holds its own statistics, vital for the Query Optimizer (QO). The QO, benefiting from Polaris’ cell awareness, implements a wide array of execution strategies and sophisticated estimation techniques, unlocking its full potential. In Polaris, a dataset is represented as a logical collection of cells, offering the flexibility to distribute them across compute nodes to achieve seamless parallelism.
To achieve effective distribution across compute nodes, Polaris employs distributions that map cells to compute nodes and hash datasets across numerous buckets. This intelligent distribution enables the deployment of cells across multiple compute nodes, making computationally intensive operations like joins and vector aggregation attainable at the cell level, sans data movement, provided that the join or grouping keys align with the hash-distribution key.
Furthermore, partitions play a crucial role in data pruning, selectively optimizing data for range or equality predicates defined over partition keys. This optimization is employed only when relevant to the query, ensuring efficiency.
A remarkable feature is the physical grouping of cells in storage as long as they can be efficiently accessed (diagonal green and blue stripes cells in the image above), allowing queries to selectively reference entire cell dimensions or even individual cells based on predicates and operation types present in the query, granting unparalleled flexibility and performance.
The Polaris distributed query processing (DQP) operates precisely at the cell level, regardless of what is within each cell. The data extraction from a cell is seamlessly handled by the single-node query execution (QE) engine, primarily driven by SQL Server, and is extensible for accommodating new data types with ease.
Flexible assignment of cells to compute
The Polaris engine is resilient to compute failures because of the flexible cells allocation to compute nodes. When a node failure or topology change occurs (scale up or down), it’s possible to efficiently re-assign the cells of the lost node to the remaining topology. To achieve this flexibility, the system maintains a metadata state, which includes the assignment of cells to compute nodes at any given time, in a durable manner outside the compute nodes. This means that the critical information about the cell-to-compute node mapping is stored in a reliable and persistent external storage, ensuring its availability even in the face of node failures.
This design enhances the overall resilience and by adopting this approach, the Polaris engine can quickly recover from node failures or topology changes, dynamically redistributing cells to healthy compute nodes and ensuring uninterrupted query processing across the entire system.
From queries to task DAGs
The Polaris engine follows a two-phased approach for query processing:
1. Compilation using SQL Server Query Optimizer:
In the first phase, the Query Optimizer takes the query and generates all possible logical plans. A logical plan represents different ways the query can be executed without considering the physical implementation details.
2. Distributed Cost-Optimization:
In the second phase, it enumerates all the physical implementations corresponding to the previously generated logical plans. Each physical implementation represents a specific execution strategy, considering the actual resources available across the distributed system. The goal of this cost-optimization phase is to identify and select the most cost-efficient physical implementation of the logical plan. It then picks one with the least estimated cost and the outcome is a good distributed query plan that takes data movement cost into account.
A Task is a physical execution of an operator defined in the two-phased optimization. Each physical execution of an operator, as defined in the two-phased optimization, is seen as a directed acyclic graph (DAG).
A task has three components:
- Inputs – Collections of cells for each input’s data partition.
- Task template - Code to execute on the compute nodes
- Output - dataset represented as a collection of cells produced by the task. It can be either an intermediate result or the final result to return to the user.
Basically, at run time, a query is transformed into a query task DAG, which consists of a set of tasks with precedence constraints.
Task Orchestration
A new design in Polaris is a novel hierarchical composition of finite state machines. The state machine lies in its hierarchical state machine composition, which captures the execution intent. Polaris takes a different approach from conventional Directed Acyclic Graph (DAG) execution frameworks by providing a state machine template that orchestrates the execution.
By using it, Polaris gains a significant advantage in terms of formalizing failure recovery mechanisms. The state machine recorder, which operates as a log, enables the system to observe and replay the execution history. This capability proves invaluable in recovering from failures, as it allows the system to precisely recreate the execution sequence and take corrective actions as needed.
A query has 3 aspects, the query DAG, the task templates, and tasks, and it is called an entity. The execution state of each entity is monitored through an associated state machine, encompassing a finite set of states and state transitions. Each entity’s state is a result of composing the states of the entities from which it is built. By utilizing state machines to track and manage the entities’ states, Polaris gains greater control over its overall execution, promoting better coordination, and facilitating the implementation of necessary actions based on the current state.
States can be:
- Simple - used to denote success, failure, or readiness of a task template
- Composite - It denotes an instantiated task template or a blocked task template
A composite state differs from a simple state in that its transition to another state is defined by the result of the execution of its dependencies.
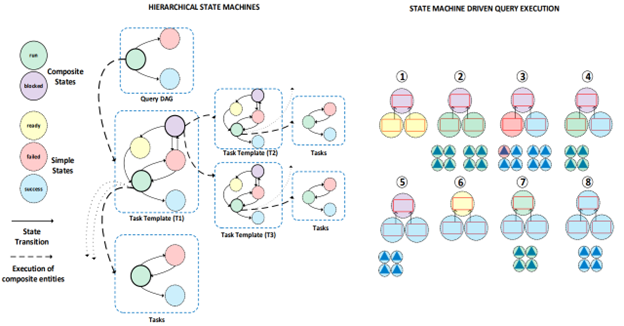
In summary, the hierarchical state machine composition in Polaris ensures a structured representation of execution intent, providing better control over query execution, recovery from failures, and the ability to analyze and replay execution history.

Migrating to Fabric Warehouse
In this eBook, we will outline how Microsoft Fabric can significantly reduce the issues facing traditional data warehousing and provide a scalable platform for future growth.
Get the eBookService Architecture
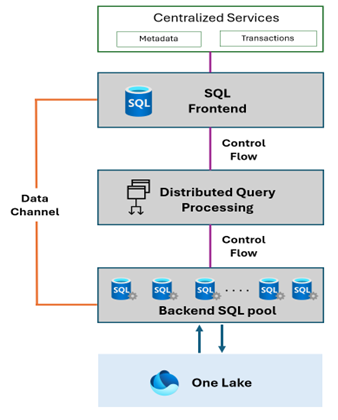
Polaris Architecture
The Polaris architecture and all services within the pool are stateless. Data is stored remotely and is abstracted via a data cell. Metadata and transaction log state are off-loaded to centralized services. It means that two or more pools will share metadata and transaction log state. Placing the state in centralized services coupled with a stateless micro-service architecture within a pool means multiple compute pools can transactionally access the same logical database.
The Polaris architecture incorporates a stateless design. Data storage is maintained remotely and takes the form of an abstract data cell. The management of metadata and transaction log states is delegated to centralized services, facilitating shared state utilization among two or more pools. This strategy empowers multiple compute pools to achieve transactional access to a shared logical database.
The SQL Server Front End (SQL-FE) is the service responsible for compilation, authorization, authentication, and metadata.
The Distributed Query Processor (DQP) is responsible for distributed query optimization, distributed query execution, query execution topology management, and workload management (WLM).
Finally, a Polaris pool consists of a set of compute servers each with a dedicated set of resources (disk, CPU, and memory). Each compute server runs two micro-services:
- Execution Service (ES) - that is responsible for tracking the life span of tasks assigned to a compute container by the DQP
- SQL Server instance - that is used as the backbone for the execution of the template query for a given task and holding a cache on top of local SSDs
The data channel serves a dual purpose: it facilitates the transfer of data between compute servers and also acts as the pipe through which compute servers transmit results to the SQL Frontend (FE).
Tracking the complete journey of a query is the control flow channels responsibility and tracks the progression of the query from the SQL FE to the DQP and subsequently from the DQP to the Execution Server.
Migrate Traditional Data Warehouses to Fabric Modern Warehouse. Watch Now.
Auto-Scale
As demand fluctuates, the Polaris engine requests additional computational resources, effectively requesting more containers from the underlying Fabric capacity. This adaptive approach ensures seamless accommodation of workload peaks. Behind the scenes, the engine adeptly redistributes tasks to newly added containers, all the while maintaining the continuity of ongoing tasks. Scaling down is transparent and automatic when the workload drops utilization.
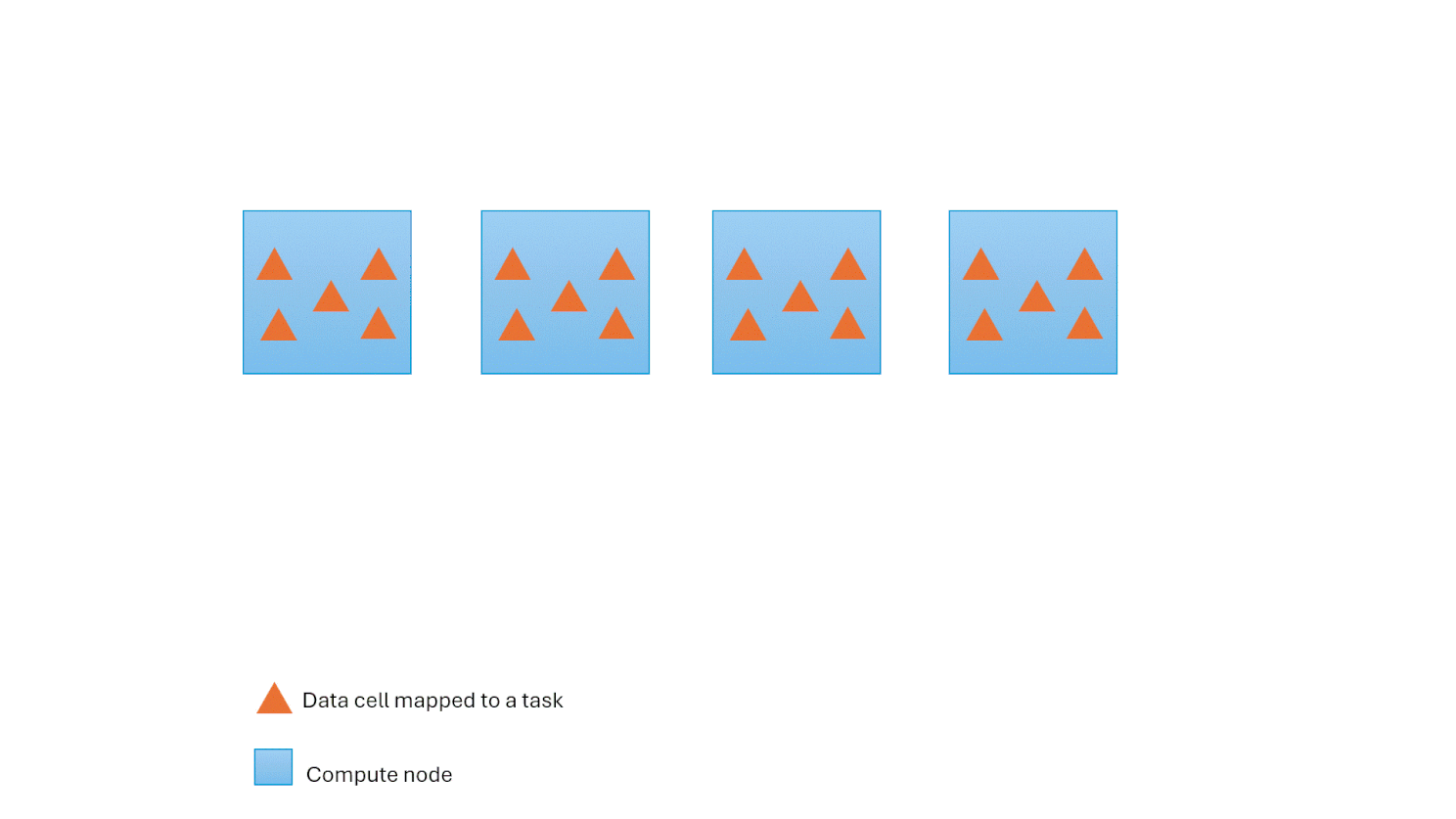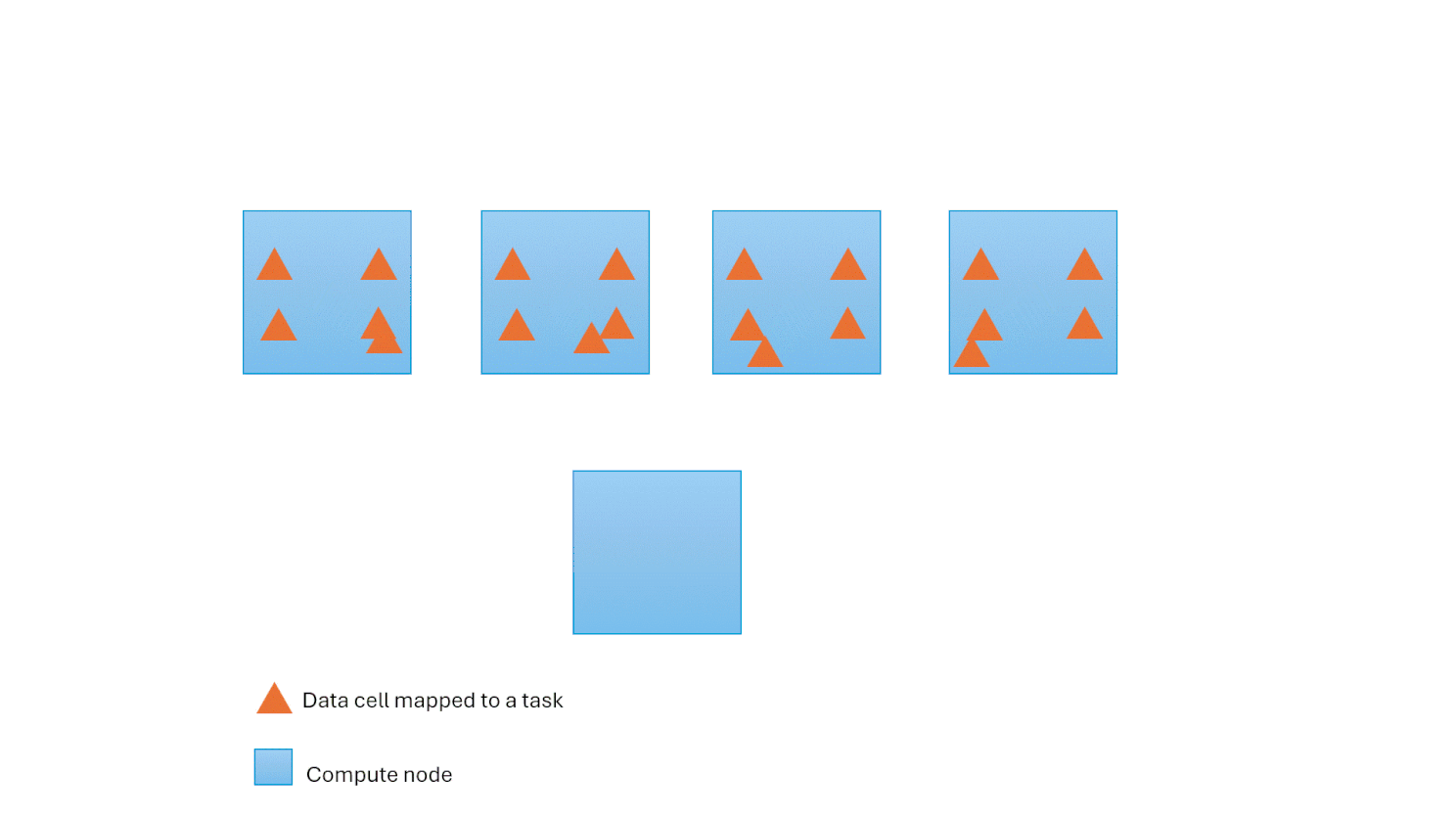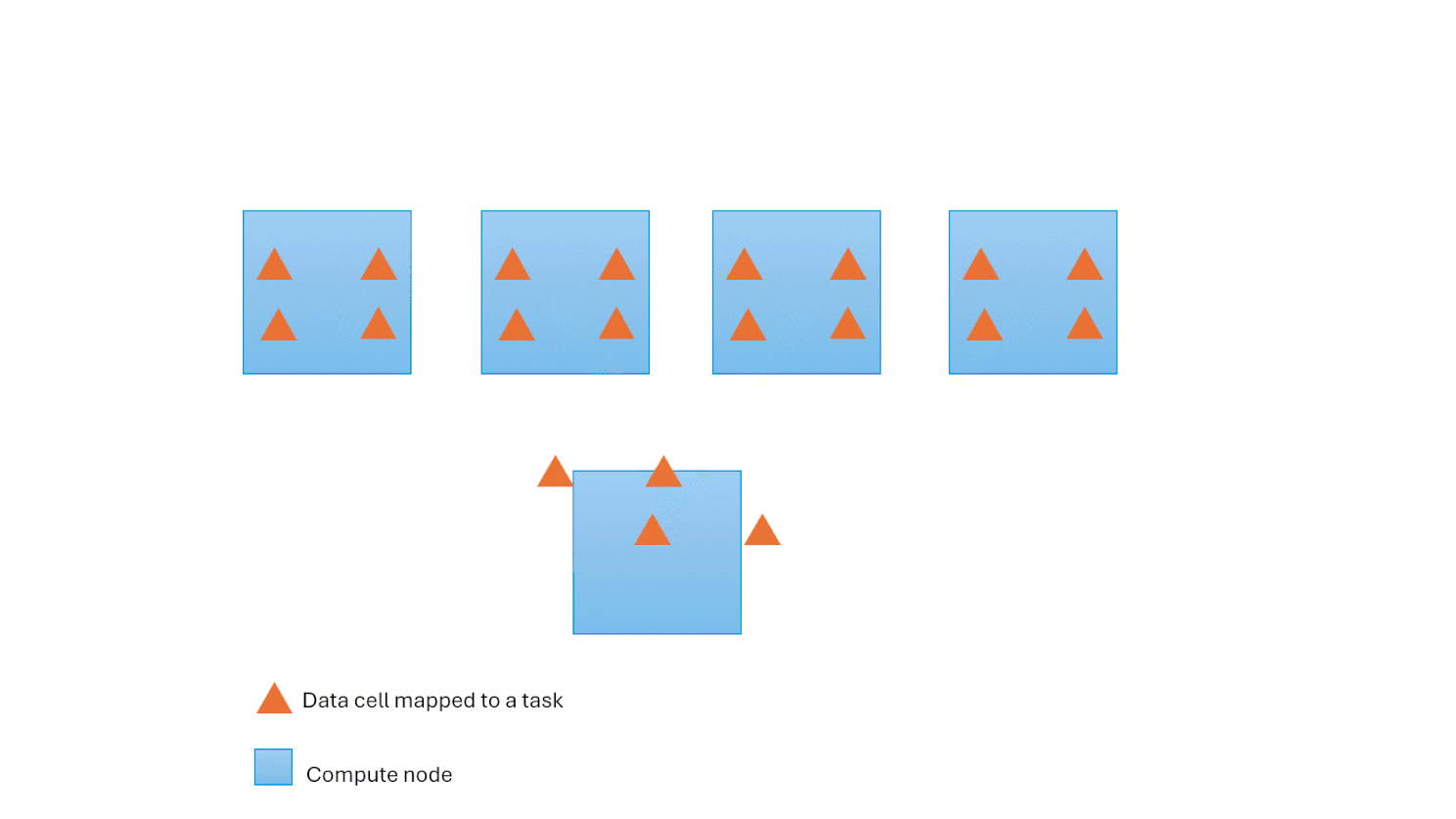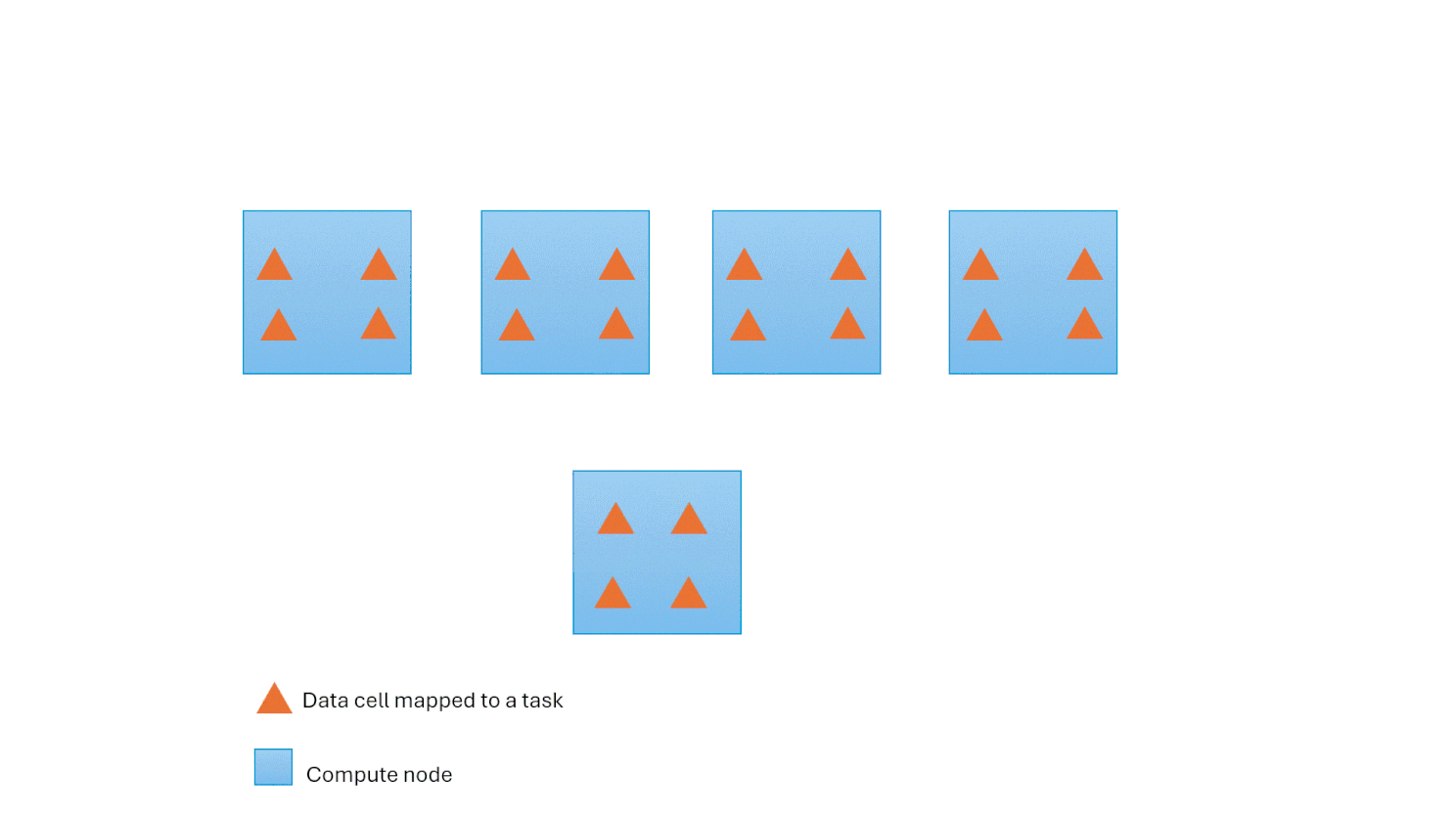
Resilience to Node Failures
The Polaris engine is resilient by autonomously recovering from node failures and intelligently redistributing tasks to healthy nodes. This functionality is seamlessly integrated into the hierarchical state machine, as discussed earlier. This mechanism plays a critical role in enabling effective scalability for large queries since the probability of node failure increases with the number of nodes involved.

Hot spot recovery
The Polaris engine manages challenges like hot spots and skewed computations through the integration of a feedback loop between the DQP and the Execution Service. This mechanism monitors the lifecycle of execution tasks hosted on nodes. Upon detecting an overloaded compute node, it automatically redistributes a subset of tasks to a less burdened compute node, If this doesn’t mitigate the issue, the Polaris engine seamlessly falls back to its auto-scale feature, which enables the addition of computational resources to effectively mitigate the issue.
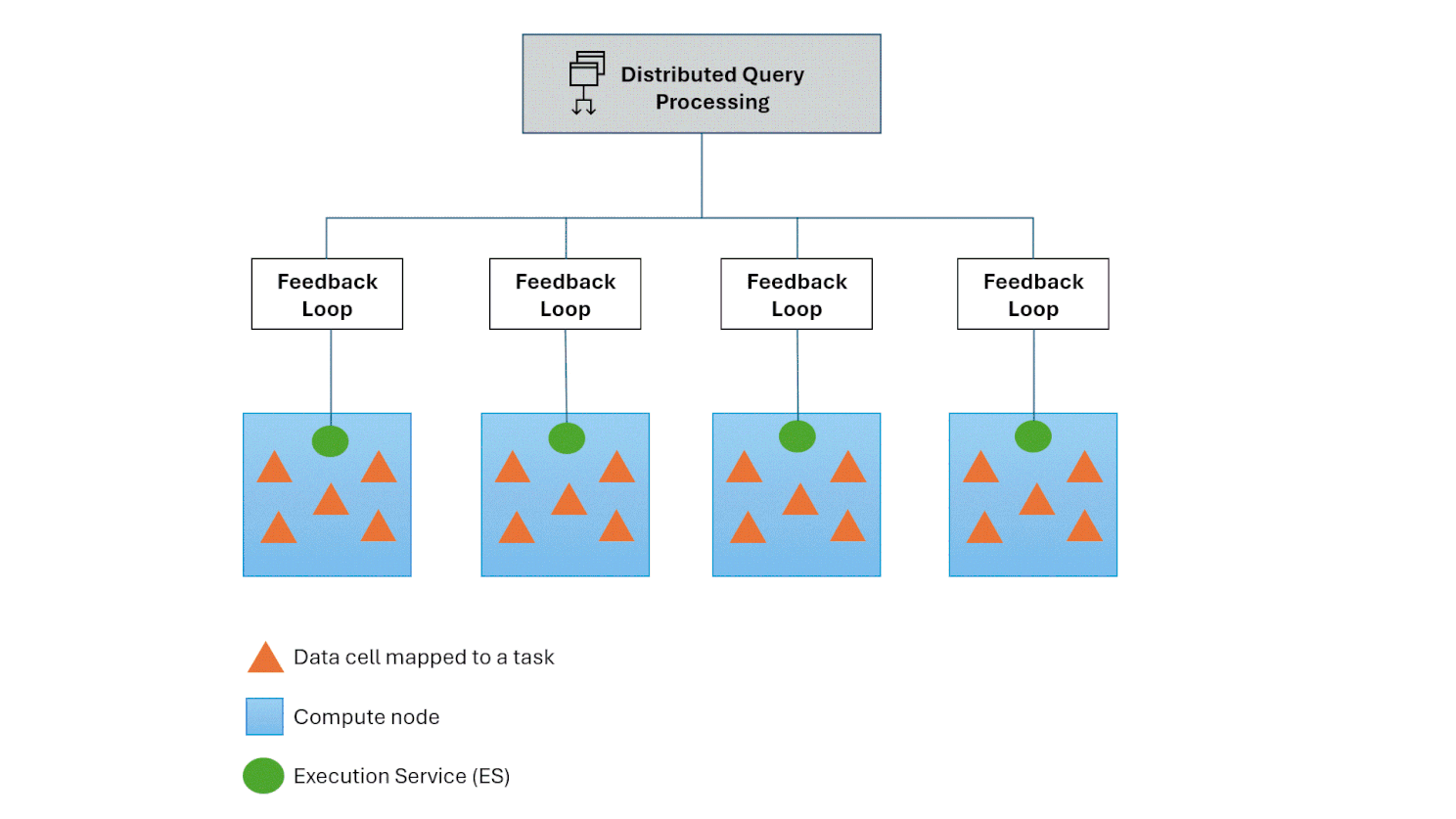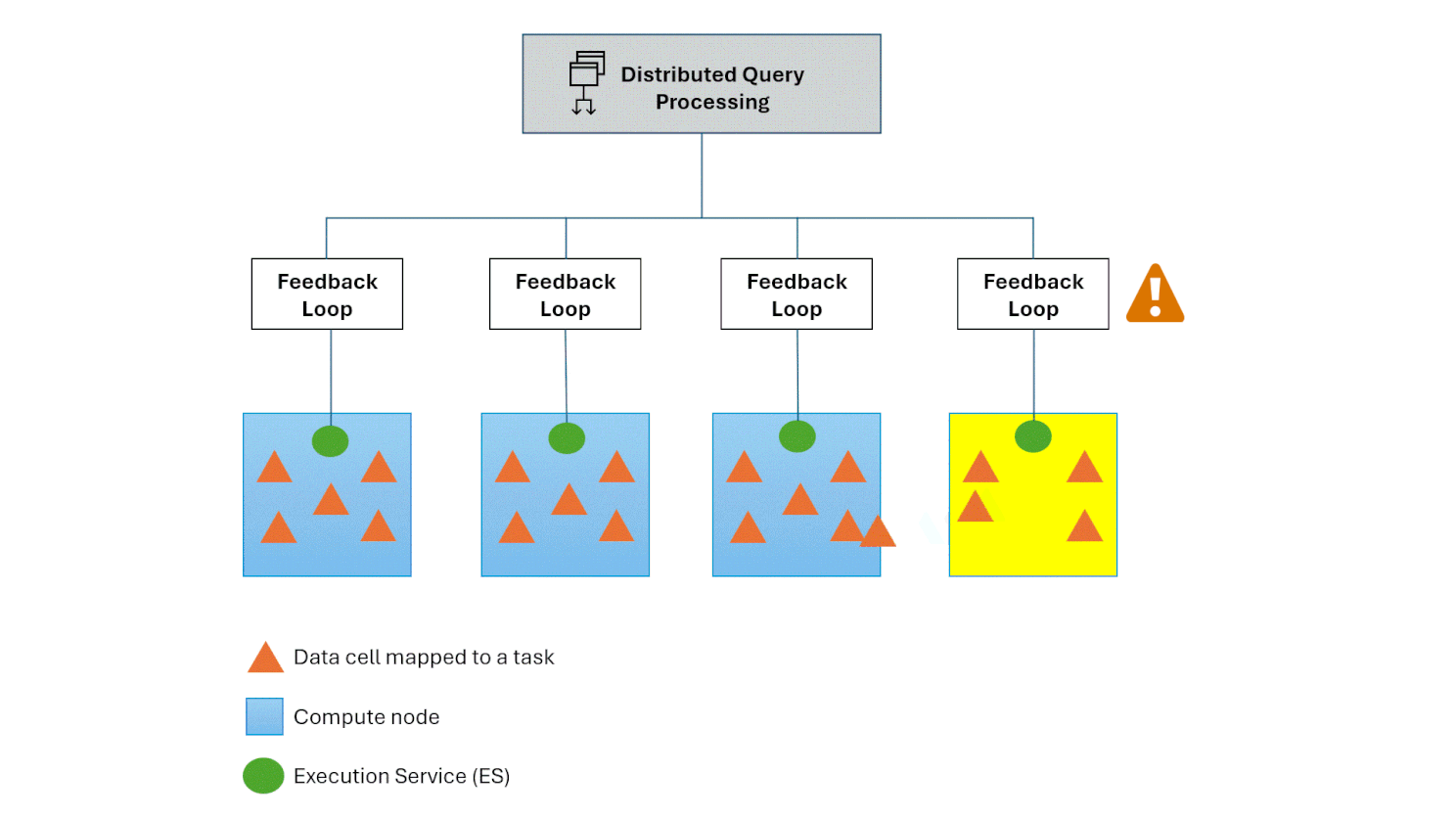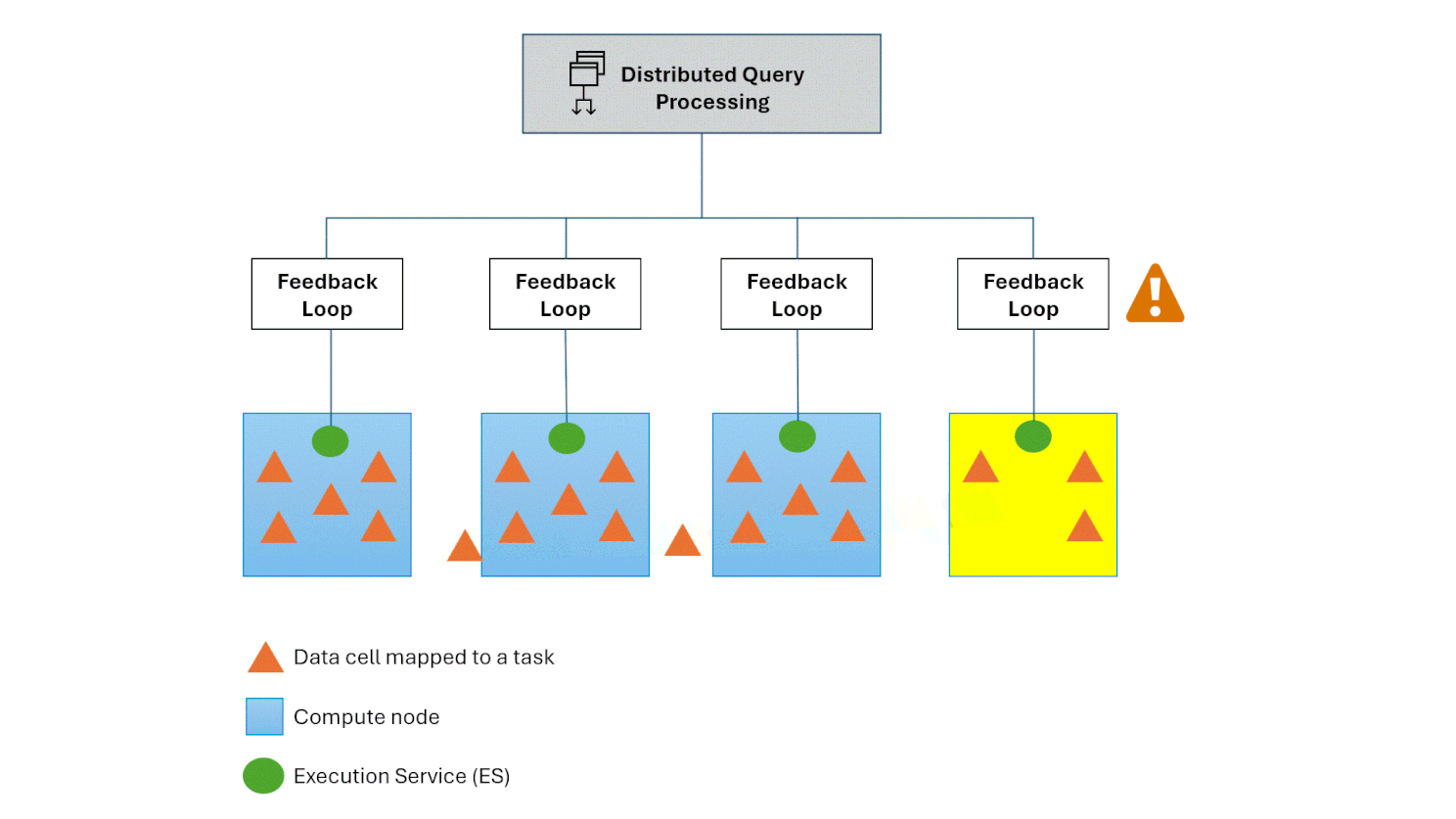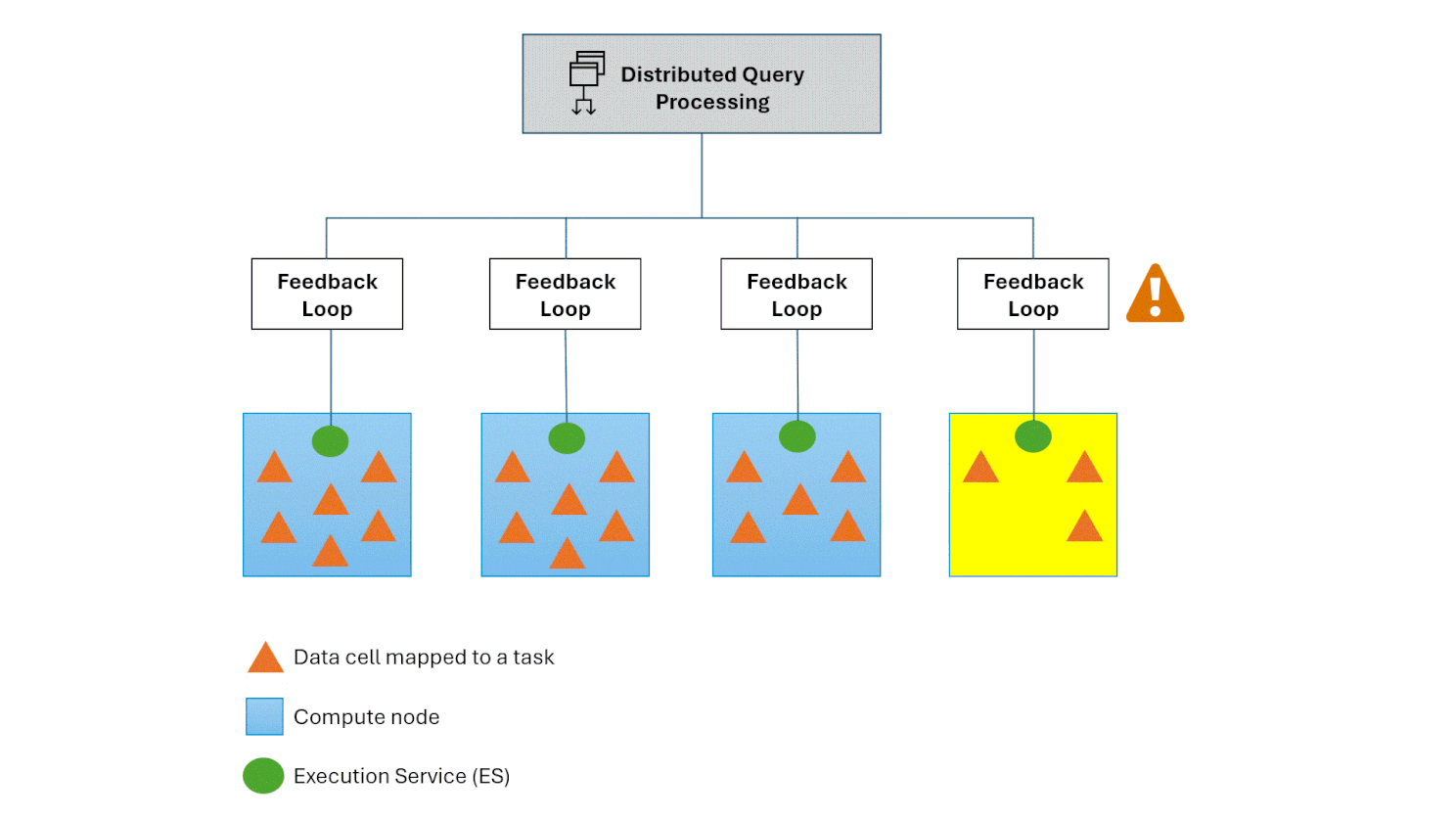
Conclusion:
Separation of state and compute. Flexible abstraction of datasets as cells. Task inputs are defined in terms of cells. Fine-grained orchestration of tasks using state machines will give more flexibility and scalability.
Delta Optimized V-order – write time optimizations to parquet file format V-Order works by applying special sorting, row group distribution, dictionary encoding and compression on parquet files will bring all data into open file format which will perform all bin compaction hence no need of writing manual code for cleanup of data. Polaris is cloud-native which now supports both big data and relational warehouse workloads and the stateless architecture provides flexibility and scalability.
Though some of the functions from the dedicated SQL pool (DW) are missing, we feel Fabric Data Warehouse is promising. We are working on a benchmark comparison in our next blogs.
Disclaimer: – Some of the content presented in this blog is from the original Reasearch paper from PVLDB Reference Format: Josep Aguilar-Saborit, Raghu Ramakrishnan et al. VLDB Conferences. Microsoft Corp. We have added our comments and views.