Introduction:
In today’s data-driven world, organizations are continually seeking innovative approaches to manage and harness the power of their data. Two emerging concepts that have garnered significant attention are Data Fabric and Data Mesh. Both aim to address the challenges of handling vast amounts of data, but they do so in distinct ways. In this blog, we’ll explore the key principles, benefits, and considerations of Data Fabric vs Data Mesh to help you make informed decisions about your data architecture strategy.
What is Data Mesh
- Domain-oriented decentralized data ownership and architecture
- Data as a product
- Self-serve data infrastructure as a platform
- Federated computational governance
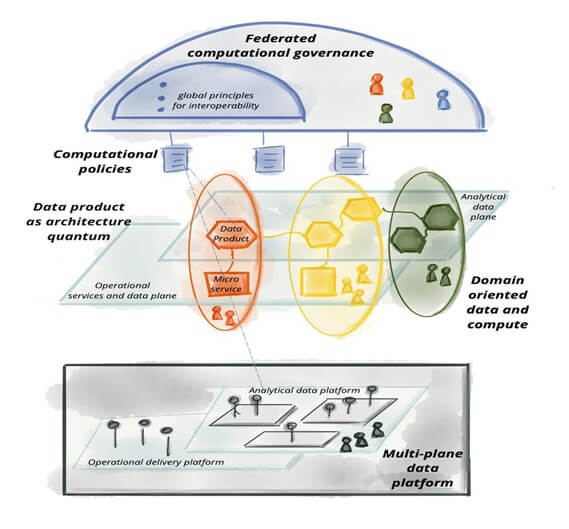
What is Data Fabric
- Augmented Data Catalog
- Persistence Layer
- Knowledge Graph
- Insights and Recommendations Engine
- Data Preparation and Data Delivery Layer
- Orchestration and Data Ops
- Automation AI/ML
- APIs
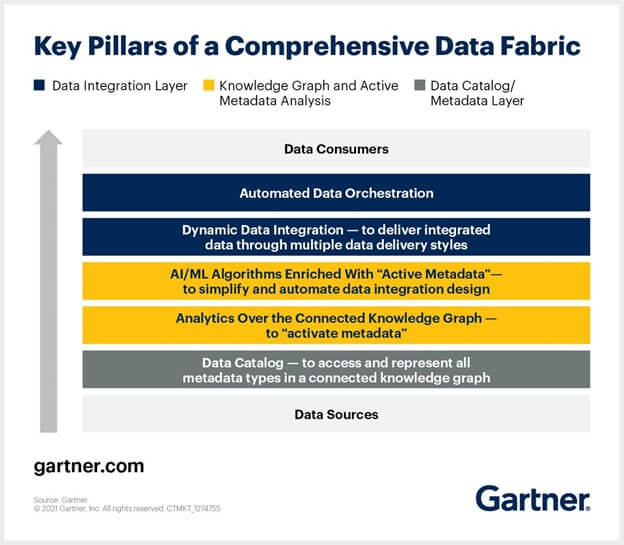
Data Fabric vs Data Mesh: What’s the difference?
- The difference between the two concepts lies in how users access data.
- Data fabric and data mesh provide architecture to access data across multiple technologies and platforms. “But a data fabric is technology-centric, while a data mesh focuses on organizational change.
- Data fabric represents a comprehensive integrated architectural layer facilitating the connection between data and analytical processes. It utilizes pre-existing metadata assets to facilitate the design, deployment, and effective management of data. The objective of data fabric is to expedite the derivation of insights from data via automated processes and offer real-time analytics. It seamlessly merges data and analytics, aiming to provide timely insights.It acts as a management solution, enabling seamless access within a distributed environment. AI/ML is inbuilt.
- Data Mesh is a highly decentralized data architecture equipped to address challenges including lack of ownership of data, lack of quality data and scaling bottlenecks. The goal of data mesh is to treat data as a product, with each source having a data product owner who could be part of the cross-functional team of data engineers. Data mesh — introduced by Zhamak Dehghani of Thoughtworks in May 2019– overcomes the problems of traditional data lakes and data warehouses.
- Data Fabric fits under Data Mesh very well.

Unlocking the Potential of Microsoft Fabric in Modern Advanced Analytics
In this comprehensive Ebook, we invite you to embark on a transformative journey, delving into the cutting-edge capabilities of Microsoft Fabric and OneLake.
Get the eBookApproach:
Automation vs Human Inclusion
- Data Mesh adopts a people- and process-centric approach towards data, treating it as a product.
- Data fabric harnesses both human and machine capabilities to access data in its original location or facilitate consolidation when necessary. It integrates technologies to link various data sources, types, and locations, employing diverse methods for data access.
- Gartner uses the analogy of a self-driving car to illustrate this concept:
- Data fabric acts as a passive observer, monitoring data pipelines and suggesting more efficient alternatives. As both the data “driver” and machine learning algorithms become accustomed to recurring scenarios, they complement each other by automating routine tasks, allowing leaders to focus on innovation.
Data storage: Centralized vs Decentralized.

Data access: APIs vs-controlled datasets
- Within Data Mesh, data is accessible through controlled datasets. Initially, data is extracted from departmental data stores and consolidated into a unified location.
- In Data Fabric, data is accessed through purpose-driven APIs. Data is segregated into tailored datasets for particular use cases, with the respective business unit maintaining control over the data.
- Data fabric continuously identifies, connects, and enriches real-time data from different applications to discover relationships between data points. It does so by building a graph storing interlinked data descriptions that algorithms can use for business analytics.
Data Fabric Vs. Data Mesh: Main Differences
| Data Fabric | Data Mesh | |
|---|---|---|
| Architecture | Data is centralized. Data made available through APIs. Aims to eliminate human effort with machine learning and AI. | Data is stored within each domain of a company. Data is copied into specific datasets for specific use-cases. Less emphasis on AI, since work is handled by domain experts. |
| Benefits | Self-service data consumption and collaboration. Automates governance, data protection, and security. Automates data integration and data engineering. | Agility and scalability with fast access and accurate data delivery. Platform connectivity and data security. Robust data governance and end-to-end compliance. |
| Use Cases | Business applications – challenges of data availability and reliance for business applications. Data discovery – what data is available and where. Machine learning – minimizes the data preparation phase when training ML models. | Financial sector – fast fraud threat analysis without copying data to a central database. Sales and marketing – targeted campaigns based on user profiles. Machine learning – create virtual data warehouses as a basis for training ML models. |
Don’t miss this opportunity to expand your knowledge and harness the full potential of Microsoft Fabric. Watch Now.
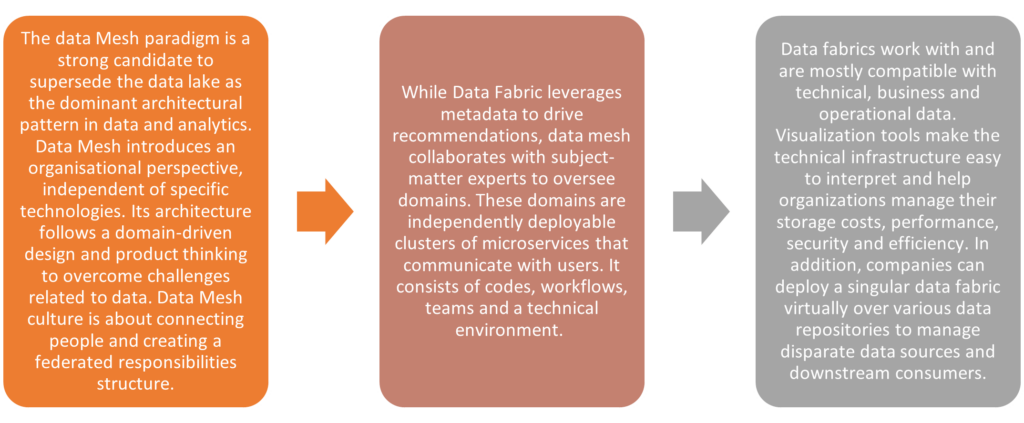
It’s essential to recognize that data mesh and data fabric are not mutually exclusive concepts. Organizations have the opportunity to utilize both approaches in various use cases.
- Data Mesh is ideal for hybrid cloud networks.
- Data fabric enables single-point data access, address data quality and storage issues and handling of security threats.
- The distinction between the two concepts lies in the way users retrieve data.
- Data fabric and data mesh offer architectural solutions for accessing data across diverse technologies and platforms. However, a data fabric centers around technology, whereas a data mesh prioritizes organizational transformation.
- Data mesh emphasizes people and processes over architecture, whereas a data fabric is an architectural approach that adeptly addresses the intricacies of data and metadata in a cohesive manner.
Architecture
Conclusion on Data Fabrics vs Data Mesh
- To summarize, both data fabric and data mesh provide powerful solutions to make your organization data-driven and even data-led. Data fabric allows everyone (within permission) easy access to data at the right time. Data mesh takes a decentralized approach by keeping separate domain-specific datasets.
- Choosing one over the other essentially boils down to the problem your organization is dealing with.