Data is produced for consumption!
Any data that is ever produced has a sole objective of being consumed by some person or application at the right time to trigger an action, help with some decision making or something else. Data characteristics like format, type, structure, schema, etc. may vary depending on the objectives of the consumer. That’s why understanding of the consumer needs is important so that data can be processed, packaged, and served as per the specific needs of the consumer.
What it takes to build a consumer centric data model?
To facilitate a consumer centric data culture, the data architecture should support few key principles:
Personalization:
The architecture focuses on tailoring data experiences to individual users or groups. This might involve recommending relevant data, providing personalized dashboards, or offering data in formats that suit each consumer’s preferences.
Ease of Use:
The architecture emphasizes simplicity and user-friendliness. It ensures that consumers can easily access, search, and understand the data they need without requiring advanced technical skills.
Data Accessibility:
Consumer-centric architecture ensures that data is easily accessible to authorized users. It might involve implementing secure authentication and authorization mechanisms to control who can access specific data sets.
Data Quality:
High data quality is a priority to ensure that the information available to consumers is accurate, consistent, and reliable. Data validation, cleansing, and enrichment processes are often part of this architecture.
Real-time or Near-real-time Access:
Depending on the needs of the consumers, the architecture might provide real-time or near-real-time access to data. This is particularly important for time-sensitive decision-making.
Scalability and Performance:
The architecture should be able to handle growing amounts of data and increasing numbers of users without sacrificing performance. Scalability ensures that consumers can interact with the data smoothly even as the system grows.
Integration:
Consumer-centric architecture often involves integrating data from various sources to provide a comprehensive view. Integration might include both internal and external data sources.
Feedback Loop:
The architecture should allow consumers to provide feedback on data quality, relevance, and usability. This feedback loop helps improve the architecture over time.
Data Governance:
Consumer-centric architecture includes mechanisms for data governance, including data lineage, data cataloging, and ensuring compliance with data privacy regulations.
Analytics and Insights:
The architecture should support data analytics and reporting, allowing consumers to gain insights from the data and make informed decisions.
Flexibility:
The architecture should be adaptable to changing consumer needs and evolving data requirements. It might involve using technologies like APIs to enable easy integration with various tools and applications.
Overall, consumer-centric data architecture seeks to create an environment where data is not just stored and managed but is also effectively utilized to meet the needs of users, whether they are business analysts, executives, customers, or any other stakeholders relying on data-driven insights.

Unlocking the Potential of Microsoft Fabric in Modern Advanced Analytics
In this comprehensive Ebook, we invite you to embark on a transformative journey, delving into the cutting-edge capabilities of Microsoft Fabric and OneLake.
Get the eBookModern data lakehouses using medallion architecture to address consumer needs
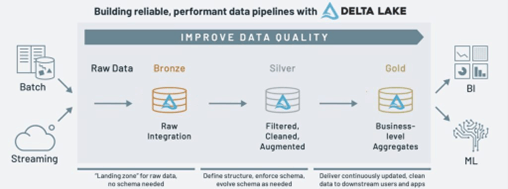
Medallion Architecture was conceived and has gained popularity due to its ability to handle large volumes of data and provide scalability, flexibility, and performance. The Medallion Architecture represents a logical data design pattern that facilitates progressive improvement in data quality, refinement, and preparation as data flows through distinctly identifiable layers, commonly named Bronze, Silver, and Gold. Hence, the word Medallion. The number of layers however is not set in stone. A situation may demand additional layers at the beginning or end.
This architecture, however, is not a replacement for dimensional modeling patterns. You can design schemas and tables in each layer as per the data usage objectives.
Bronze Layer:
This is the raw data layer where data from various sources is ingested without much processing. It is like the initial stage of landing data in a data lake.
Silver Layer:
In this layer, data is refined, transformed, and cleaned. This is where data is enriched, standardized, and made ready for analysis. It is a layer between raw data and fully refined data.
Gold Layer:
This is fully refined and curated data that is ready for consumption by analytics and reporting tools. It is the layer where data is optimized for query performance and is typically used for business insights.
We will be discussing considerations and data planning strategies for each layer later in this article.
Microsoft Fabric Lakehouse has all the right elements for medallion architecture
Microsoft Fabric introduced the concept of one data lake (One Lake) for the entire organization and one copy of data for use with multiple analytical engines. Within One Lake, data ownership is established with Workspaces. Data can be copied or streamed into any Workspace to a lakehouse from any of the diverse sources. Alternatively short cuts can be used to access data from internal or external sources without copying within a data lakehouse.
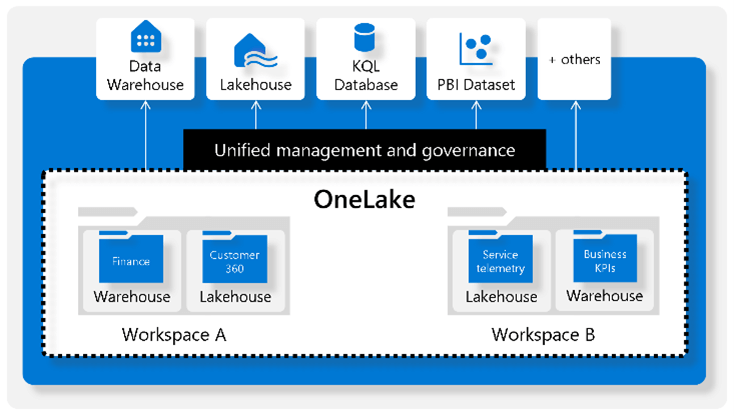
Data item structured or unstructured is always stored in delta parquet format. This along with delta lake implementation in Fabric ensures consumers with different persona and having distinct perspective can access same data item from different compute engines without ever having to create copies of the data item. This simplifies data governance.
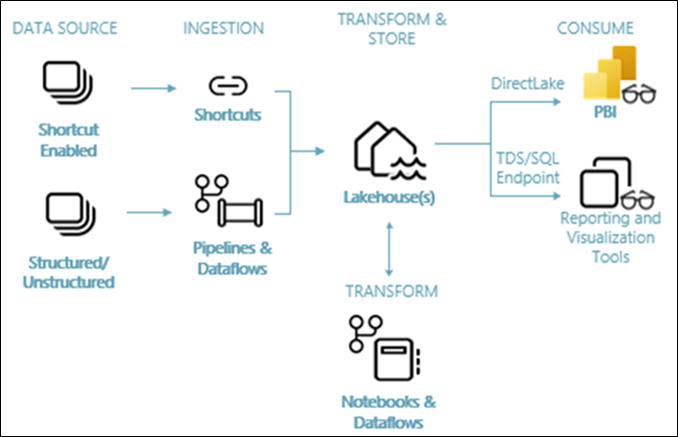
A review of the Fabric lakehouse architecture would make it clear that components are in perfect alignment with medallion architecture objectives.
Raw data can be ingested into one lakehouse if all of the data belongs to a single region. If there is need for internal data protection or boundaries data can be stored over multiple bronze lakehouses.
Raw data can be processed for transformation, cleansing, enrichment, etc. using Notebooks or Dataflows that have access to all bronze lakehouse data. Data in this layer is typically not aggregated.
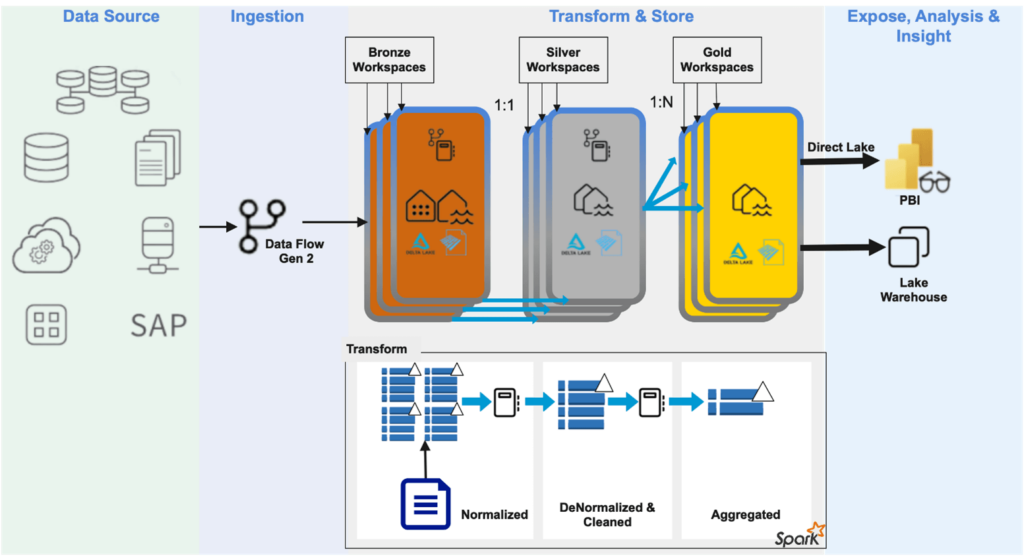
Transformed data can be saved in other dedicated lakehouses or better still in one or more separate workspace(s) termed as silver layer. You should consider multiple workspaces in a silver layer if different business groups are responsible for the cost of processing for their data need.
Gold data is typically directly consumed by business groups. Each group has their own expectations from data mapped to their business objectives. Because objectives may vary, it is best to isolate data for these target groups in separate silos. In Fabric, Gold layer may consist of one or more workspaces. Typically, one to many relationships works best between silver and gold datasets. Using Notebooks or Dataflows in silver workspace, data can be aggregated to its final curated form for ready consumption in Power BI or other analytical applications.
Don’t miss this opportunity to expand your knowledge and harness the full potential of Microsoft Fabric. Click here to watch our webinar.
Native support for consumer expectation from the architecture
We can seamlessly map most of the consumer-centric data architecture principles described earlier in this article with the Fabric Lakehouse architecture described above. Presentation of data through schemas relevant to target user groups in isolated workspaces or lakehouses ensured delivery of personalized data to users. Transformation from raw data to schemas suitable for different target groups happens in parallel with excellent performance guarantee because of underlying Spark cluster. The architecture can deliver transformations in scale because of the same Spark cluster. Delta lake configuration ensures that user groups with varied sets of analytical tools and applications can work on same set data as Fabric supports SQL interface as well as Lakehouse interface. Fast processing and interface of choice ensures near real time access to processed data in the preferred format. Schema validations at silver and gold lakehouses guarantee high data quality and trigger feedback loops for data quality issues originating at source or during processing.
Conclusion
To summarize, Microsoft Fabric comes with a great promise to materialize the vision of servicing consumers with data as customized product which can be used directly to achieve desired objectives. Watch out for an eBook where we would walk through steps of creating this architecture for different use cases with sample datasets.