Introduction
Like hundreds of leading enterprises, you probably have realized that treating data as assets, closely managed by a highly specialized central team is creating huge bottleneck for actual data owners and consumers.

If you are still continuing with a centralized data culture, you might be feeling constrained trying to scale appropriately to accommodate huge influx of data volume, diversity and demand for data driven insight.
If you have reached here from Google search, you must already be contemplating seriously a transition to a culture where data should be managed in the domain, that owns the data and domains are responsible for sharing data with others inside or outside the organization.
Why monolithic data architecture is not supporting big enterprises anymore?
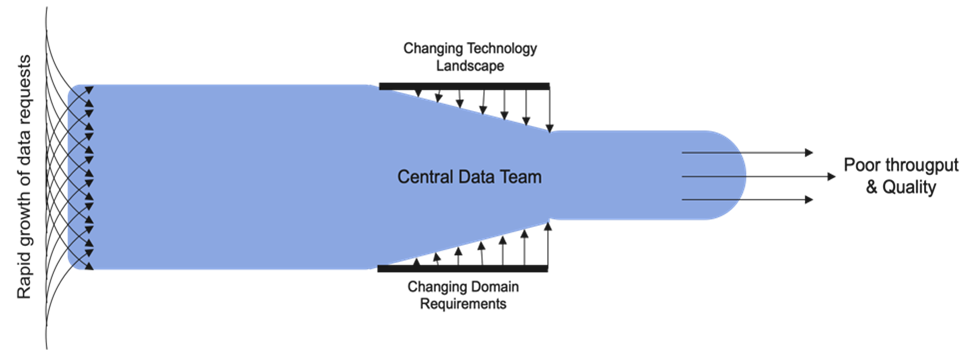
Monolithic data architectures like data warehouses and data lakes, were designed with the concept of storing and serving an organization’s vast amount of operational data in one centralized location. The thought process was that the specialized data team would ensure the data is clean, accurate and properly formatted. The data consumers are expected to be served with high quality contextual data for wide range of analytical use cases. However, in reality, this is not always the case. While centralization strategies have witnessed initial success for organizations with smaller data volume and fewer data consumers, with the increase of data sources and consumers, it started to develop bottlenecks.
As enterprises grow, their data requirements become more complex. Monolithic architectures are often difficult to scale horizontally to meet increased data volumes and processing demands. This can lead to performance bottlenecks and limit an organization’s ability to handle big data effectively. As enterprises grow, their data requirements become more complex.
Monolithic architectures are often difficult to scale horizontally to meet increased data volumes and processing demands. .This can lead to performance bottlenecks and limit an organization’s ability to handle big data effectively.
Over 80% of enterprise data remains as Dark Data. This data does not help organization with any insight to make any business decision.
Modern enterprises deal with a wide variety of data types, including structured, semi-structured, and unstructured data. Monolithic architectures are typically optimized for handling structured data, making it challenging to efficiently process and analyze diverse data sources. Different business units of an enterprise might have completely different data needs in terms of source, data types and processing logic. Accommodating all of these diverse requests has become really challenging for a central team both in terms of domain knowledge and technology involved. This results in mounting frustrations among data owners and consumers and much of data may not even be referred to the central data team. As a result, a lion’s share of enterprise data remains unexplored – referred as Dark Data.
We can summarize the challenges of enterprises having a monolithic data architecture as below:
- Disconnects data and data owners (product/service experts).
- Data processing architecture is not in alignment business axis of change.
- Tight coupling between stages of data processing pipeline impacts flexibility that business needs.
- Creates highly specialized and isolated engineering team
- Creates backlogs focused on technical not on business functional changes.
How Data Mesh i.e., domain centric federated data management is helping big enterprises?
Data Mesh is founded on four principles:
Domain Oriented Ownership
Data is owned and managed by the teams or business units (domains) that generate and use it. This aligns data responsibility with the domain’s expertise, making it more manageable and relevant to its specific context.
Data as a Product
Data is treated as a product rather than a byproduct of business processes. Each domain is responsible for creating and maintaining its own data as a product, which is designed to meet the needs of the domain’s consumers. Data products include well-defined data sets, APIs, and documentation.
Self-serve Data Platform
Development of self-serve data infrastructure that enables easy and secure access to data for data consumers. This infrastructure includes data catalogs, data discovery tools, and standardized interfaces for accessing data products.
Federated Computational Governance
A structured approach to governance within a data mesh. It ensures that domains maintain a degree of independence while adhering to essential governance standards, fostering interoperability, and enabling the organization to leverage the full potential of its data ecosystem. This approach relies on the fine-grained codification and automation of policies to streamline governance activities and reduce overhead.
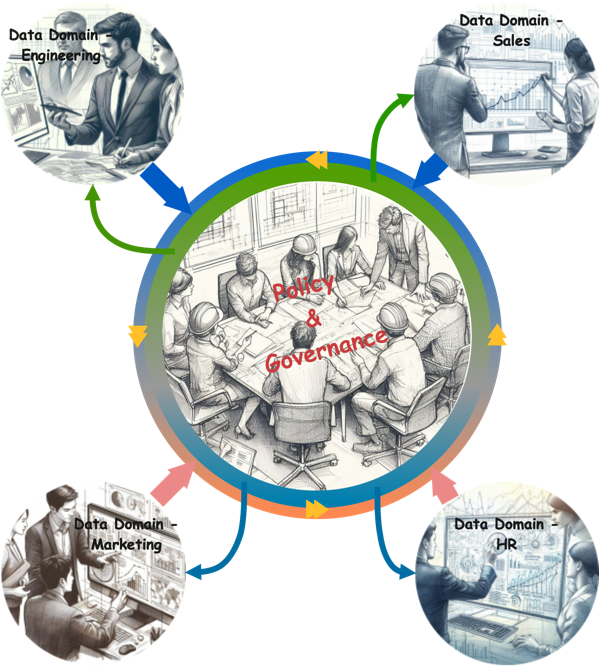
The basic concept of Data Mesh is simple – help data owners like functional or business units, manage their own data as they understand their data best. Removing dependency on a central data team, domains can enjoy autonomy and can scale as needed.
Along with the independence comes accountability as a single team is responsible for the data from production to consumption. This encourages domain teams to take responsibility for the quality, accuracy, and accessibility of their data. This, in turn, can lead to better data governance and more reliable data.
As domains take the ownership of data, they ensure that potential consumers of their data, be it other domains within the organization or external consumers, can easily discover, trust and access data. Also, they ensure published dataset follow certain standards in terms of schema and metadata so that data can be interoperable with another dataset. This is where product mindset becomes relevant, and data is managed and published as product. This makes it easier for data consumers to find the data they need, fostering self-service analytics and reducing the time and effort required to locate relevant information.
Domain-centric architectures are designed to scale with an enterprise’s growing data needs. When new domains or data sources are added, they can be integrated without significantly affecting existing domains. This flexibility allows organizations to adapt to changing business requirements and incorporate new data sources and technologies more easily.
Data silos are a common problem in large enterprises. A domain-centric approach helps break down these silos by promoting collaboration and data sharing between different parts of the organization. Domains can act as data product teams, providing standardized, well-documented data interfaces for others to use.
Domain-centric architectures encourage smaller, more focused teams to develop and manage data products. This can lead to quicker development cycles, faster iterations, and the ability to innovate more rapidly. It also reduces the risk of bottlenecks in data delivery. Also, because of the ownership, teams are more likely to ensure data quality and consistency within their specific domains. This can result in better data reliability and trustworthiness across the enterprise.
What kind of challenges enterprises face while adopting domain centric data management?
Analysis of experiences of some enterprises, challenges companies face adopting domain centric federated model can be classified mainly under three categories:
- Management acceptance
- Dealing with cultural shift
- Governance challenges
We need to accept this is a significant change that needs support from top management in pushing down the change through ranks of organization. The main challenge is structural. For decades industries are habituated in dealing data in centralized manner. Organization roles and responsibilities got defined accordingly. Changing over to data federation model, threatens to significantly alter scope of those roles. Along with that, domains need to be equipped with skills, infrastructure and controls to perform data processing and management on their own.
While each domain has autonomy, there’s a need for consistent data governance across domains. Coordinating and enforcing data governance policies at the enterprise level while allowing autonomy at the domain level can be a delicate balance. This applies to both consistent data quality and interoperability of data produced by different domains. Ensuring that each domain adheres to the enterprise’s data quality standards while allowing flexibility for domain-specific requirements is a delicate task. Similarly, ensuring each domain adhere to similar data formats, schemas, or data processing technologies is crucial.
To overcome these challenges, a dedicated team empowered by top management’s commitment need to work in phases with different domains, beginning with few pilot transitions. Doing pilot programs with most willing groups increases the chance of early success and helps wins trust of others across the organization.

Treat Your Data as Product with Microsoft Fabric
Welcome to a new era of data management and transformation! Our latest ebook, “Treat Your Data as Product with Microsoft Fabric”, is your definitive guide to revolutionizing the way you perceive, manage, and leverage your data assets.
Get the eBookBonus Read: Data Fabric vs. Data Mesh
Microsoft Fabric will help ease transition challenges
Microsoft Fabric has been designed to support organizations adopt the domain centric data culture in a streamlined manner. As Data Mesh is a socio-technical endeavor, organizations need to gear themselves up for the change, while Fabric can largely address the technical aspects.
Microsoft Fabric consolidates many technologies under one platform to offer end to end data management with great flexibility to accommodate diversity in organizational culture, structure, and processes. Four principles of Data Mesh can be mapped to one or more of Fabric components.
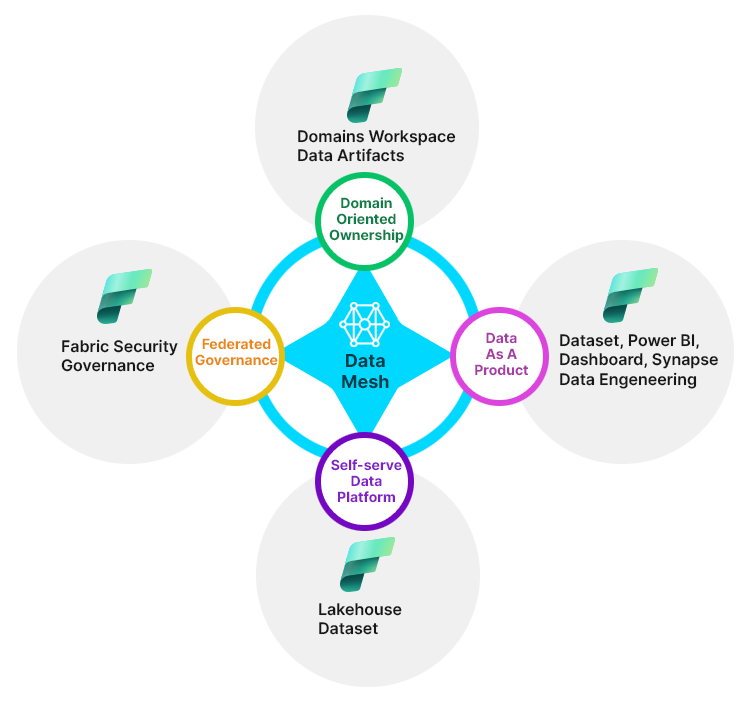
Data Mesh architecture empowers business units to structure their data as per their specific need. Organizations can define data-boundaries and consumption pattern as per business needs. Fabric allows define domains for organizations that map to business units and associating workspaces to each domain. Data artifacts like lakehouse, pipeline, notebook, etc can be created within workspaces. Federated governance can be applied to granular level through domains and workspaces.
Fabric design has also implemented framework to support dataset as product, which is a major recommendation of Data Mesh. Any dataset that is promoted from any workspace, will be listed by OneLake as available dataset and becomes discoverable. Listed dataset is published with metadata that helps consumers with information to get enough details about the dataset. Workspace owner can also mark dataset as certified, which makes the dataset trustworthy for consumers. Dataset can be published through multiple endpoints to facilitate access through native tools and methods. While doing so, specific addresses for these endpoints are also published through OneLake. This satisfies Data Product characteristics like addressable and natively accessible. Microsoft Purview is now integrated with Fabric to further bolster data discovery. So, using Fabric, organizations get the right technology support to package their datasets as product while sharing inside or outside the organization.
Fabric makes it easy for data owners to perform most of the data processing activities themselves using OneLake interface. Very little core and complex data processing and transformation skills are needed to perform such activities in Fabric. This enables a large section of business users who are actual data owners and/or consumers to do self-service on their data requirements.
In terms of Federated Governance, another principle of Data Mesh, Fabric is making significate stride in this direction. Microsoft Purview is a unified data governance service that is integrated with Fabric to enable a foundational understanding of your OneLake. Purview helps with automatic data-discovery, sensitive data classification, end-to-end data lineage and enable data consumers to access valuable, trustworthy data.
Don’t miss this opportunity to expand your knowledge and harness the full potential of Microsoft Fabric. Click here to watch our webinar.
What is your next step towards data democratization?
By now, you must agree that data democratization is a must for your organization if you envision continued growth. You do not want a severe bottleneck in the form of a centralized data architecture supported by a highly specialized team. You want to provide your business units more data autonomy so they can scale as business demands.
You also have understood that the transition is not easy as this is a techno-socio change. You do need support of a good technology platform as well as a good partner with experience of driving similar transition with other enterprises. Microsoft Fabric has a great promise to be one such platform. You may refer the eBook – Deliver your data as product for consumers using Microsoft Fabric, on detailed transition steps, challenges and Fabric features that helps you implementing Data Mesh principles for your organization.
For a workshop on your prospect of transition to Data Democratization, please contact Netwoven Inc.